La web: Sus comienzos hasta la actualidad
La siguiente entrada esta basada en un trabajo de consulta realizado para la asignatura de Despliegue de Aplicaciones Web de 2º DAW.
Nacimiento de internet
La historia de Internet se remonta al temprano desarrollo de las redes de comunicación. La idea de una red de computadoras se diseña para permitir la comunicación general entre usuarios de varias computadoras.
Internet es una gran red de redes, también llamada “supercarretera de la información”. Es el resultado de la interconexión de miles de computadoras de todo el mundo.
Las versiones más antiguas de estas ideas aparecieron a finales de los años 50. Las implementaciones prácticas de estos conceptos empezaron a finales de los 60 y a lo largo de los 70. En la década de los 80, las tecnologías que reconocemos como las bases de Internet, empezaron a expandirse por todo el mundo. Finalmente, en los 90 se introdujo la World Wide Web.
Es importante, decir que Internet y el World Wide Web no son la misma cosa. La Web es parte de Internet, y simplemente lo usa para transmitir información entre los equipos.
La web 1.0: Los comienzos
A partir de este momento es cuando comienza el desarrollo y la evolución de la Web, apareciendo la fase denominada Web 1.0, cuyas páginas se traducen en documentos simples constituidos únicamente por texto, los cuales eran interpretados gracias a navegadores muy rápidos (como por ejemplo ELISA).
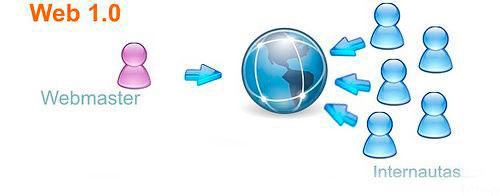
Posteriormente, y gracias a la aparición del lenguaje HTML (HyperText Markup Language), se evolucionó en el concepto de Web 1.0, pasando a convertirse en un conjunto de documentos en lenguaje HTML (lo que permitió disponer de páginas Web más agradables a la vista) interconectados mediante enlaces. Dichos documentos eran generados por una única persona (Webmaster) encargada de su diseño y de la recopilación de los datos contenidos en ellos. Fue además el comienzo de los primeros navegadores visuales (Internet Explorer, Netscape, etc.).
El principal obstáculo (limitación) que lleva consigo la Web 1.0 es que es de sólo lectura. El usuario no puede interactuar con el contenido de la página (comentarios, respuestas o citas), y se encuentra totalmente limitado a lo que el Webmaster decide publicar.
La web 2.0: Un paso hacia lo social
El término Web 2.0 se utilizó por primera vez en el año 2004 cuando Dale Dougherty (vicepresidente de O’Reilly Media) utilizó este término en una conferencia en la que hablaba del renacimiento y evolución de la Web (Web Conference).
En la charla inicial del Web Conference se habló de los principios que tenían las aplicaciones Web 2.0:
- La web es la plataforma.
- La información es lo que mueve al Internet.
- Efectos de la red movidos por una arquitectura de participación.
- La innovación surge de características distribuidas por desarrolladores independientes.
- El fin del círculo de adopción de software pues tenemos servicios en beta perpetuo.
Aunque no existe una definición consensuada, en el año 2005 Tim O’Reilly (fundador de O’Reilly Media) definió el concepto de Web 2.0 como “una serie de aplicaciones y páginas de Internet que utilizan la inteligencia colectiva para proporcionar servicios interactivos en red dando al usuario el control de sus datos”.
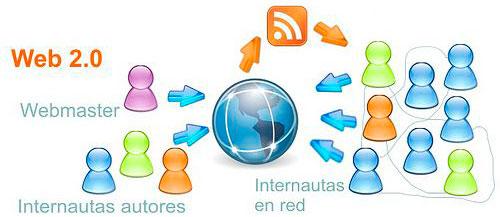
A diferencia de la Web 1.0, en el modelo Web 2.0 la información y contenidos se producen (directa o indirectamente) por los usuarios del sitio Web y adicionalmente puede ser compartida por varios portales Web de estas características. En la Web 2.0 los consumidores de información son los productores de la información que ellos mismos consumen (nace el concepto de Prosumidor).
La Web 2.0 es también llamada web social por el enfoque colaborativo y de construcción social de esta herramienta.
La web 3.0: La web semántica
Web 3.0 es un neologismo que se utiliza para describir la evolución del uso y la interacción en la red a través de diferentes caminos. Ello incluye, la transformación de la red en una base de datos, un movimiento hacia hacer los contenidos accesibles por múltiples aplicaciones non-browser, el empuje de las tecnologías de inteligencia artificial, la web semántica, la Web Geoespacial, o la Web 3D. Frecuentemente es utilizado por el mercado para promocionar las mejoras respecto a la Web 2.0. El término Web 3.0 apareció por primera vez en 2006 en un artículo de Jeffrey Zeldman, crítico de la Web 2.0 y asociado a tecnologías como AJAX. Actualmente existe un debate considerable en torno a lo que significa Web 3.0, y cual es la definición acertada.
Según los expertos, los motores de búsqueda se harán más y más concretos. Ahora, cuando hacemos una búsqueda en Internet, la información que se nos muestra es la misma a la de otro usuario. Los motores de búsqueda Web 3.0 serán más y más específicos con cada usuario y producirán diferentes resultados de búsqueda. Los buscadores 3.0 aceptarán consultas más complejas, es decir, podrás hacer la siguiente consulta: “Estoy cambiando de casa de Madrid a Barcelona y estoy buscando alojamiento ¿Cómo están los alquileres en Barcelona?”
Por lo tanto, esto supondrá que los sitios Web se harán más y más comunicativos. Estas son las principales características de la Web 3.0 en cuanto a búsquedas pero ¿qué sucede con el resto? Otra gran novedad que ya se conoce es la posibilidad de compartir la información con otros para producir resultados mucho más precisos.
Una nueva característica será la tendencia a la integración de diferentes servicios, como redes sociales. Por ejemplo, con un solo nombre podrás gestionar sus perfiles en Facebook, Twitter y MySpace.
La publicidad sufrirá un cambio importante. Así como ahora la publicidad mostrada al usuario es genérica, en la web 3.0 la tendencia será a mostrar contenidos relacionados con las búsquedas del usuario, sitios web visitados… Es decir, productos o servicios potencialmente atractivos para los usuarios. Las aplicaciones 3.0 serán diseñados de tal manera que, aunque no sean igual de inteligentes que el cerebro humano, estarán muy por delante del típico editor de textos y por lo tanto la predicción de palabras será mucho más rápida y eficaz. Dicen que será tan efectivo que algunos pueden llegar a considerarlo como una violación a su privacidad.
A modo resumen, podríamos hacer una comparativa entre web 2.0 y 3.0 como la siguiente.
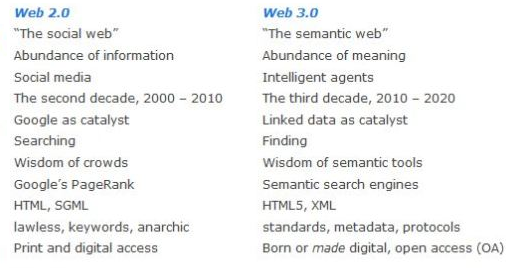
Web semántica frente a Web de datos
En definitiva, el concepto tiene que ver con los avances que permiten la incorporación de Internet a nuestras vidas de forma cada vez más eficiente, adicionalmente y según las corrientes que definen esta etapa como el paso previo a la integración total de las personas y las máquinas, el término más exacto para definirla sería Web de datos, por su naturaleza en capas de interrelacionar e interpretar el mayor número posible de datos en pos de la ampliación del conocimiento.
¿En qué consiste la Web de los datos y para qué puede ser utilizada?
Básicamente, la idea se refiere a una web capaz de interpretar e interconectar un número mayor de datos, lo que permitiría un avance importante en el campo del conocimiento.
En tal sentido, se destaca lo que esta transformación traería aparejada en el campo de la investigación genética y el tratamiento farmacológico de enfermedades hasta ahora incurables. Diseñada correctamente, la Web Semántica puede asistir a la evolución del conocimiento humano en su totalidad.
Proyectos que anticipan el modelo de la web 3.0
Dentro de la corriente oficial, centrada en la creación de estándares y formateo de páginas, algunas Compañías como HP y Yahoo ya vienen implementando los nuevos lenguajes.
Los ejemplos más citados son el de la empresa RadarNetworks , que busca explotar el contenido suministrado por los usuarios en las redes sociales y el proyecto KnowItAll, desarrollado en la Universidad de Washington y financiado por Google, que busca obtener y agregar información de usuarios de productos.
Se pueden encontrar estructuras web semánticas en la herramienta espacial de la base de datos Oracle. Empresas como Powerset y TextDigger han trabajado en buscadores web semánticos basados en el proyecto académico open source WordNet.
Por otra parte, dentro de la corriente alternativa, ocupada en la construcción de agentes más inteligentes, el proyecto más temprano ha sido el de BlueOrganizer de AdaptativeBlue.
Actualmente en desarrollo, Parakey es un proyecto de código abierto, comandado por Blake Ross, uno de los desarrolladores de Firefox. La idea es unificar el escritorio y la web, a partir de la creación de una especie de sistema operativo web.